We implemented our navigation scheme in C++ on a Sun SparcStation10 (96 Mbyte RAM) running Solaris 2.3. As alluded to previously, we used a fairly complex compositing operation for rendering. Rays were traced using a shaded surface back-to-front compositing operation. For each voxel sampled, 8-bit density data was stored. A 3D surface gradient was calculated using 6-neighbor densities at each sample along a ray. The final color assigned to the ray sample was determined by the orientation of the gradient with respect to a point-light source and the amount of ambient light present. It must be noted that the gradient computation was performed in real-time on each new voxel access. We have built an interface that allows a user to navigate through a 3D image. Per the presented algorithm, the view point can be changed from one time point to the next in essentially any direction.
We present pictorial and timing results for a ![]() Imatron CT image of the human lungs. The voxel size is
Imatron CT image of the human lungs. The voxel size is
![]() An
electron beam CT scanner, made by Imatron, was used.
The original data consisted of 40 3 mm -thick slices
gathered over a single 52-sec breath hold; this
data was interpolated to 0.5 mm z resolution. An
18kg dog was anesthetized and mechanically ventillated
during the scan (functional residual capacity---0 cm
H
An
electron beam CT scanner, made by Imatron, was used.
The original data consisted of 40 3 mm -thick slices
gathered over a single 52-sec breath hold; this
data was interpolated to 0.5 mm z resolution. An
18kg dog was anesthetized and mechanically ventillated
during the scan (functional residual capacity---0 cm
H![]() 0 lung pressure).
Figure 1a illustrates a
sample navigation sequence through the bronchial passages. Each
view, labeled View 1, View 2, etc., depicts a 3D rendered image
along the navigation path. In the center of View 1, the dark cavity surrounded by
the tube is the main bronchus (a hollow cavity). The orange structures
outside the bronchus are the lungs. Each successive view depicts
what one observes while traversing down the bronchus and into
the lung to the right. An important consideration while navigating
is to know your current orientation in the data. Fortunately, since
we have a 3D copy of the anatomy (the 3D EBCS image), we can easily
compute and display this information. Figure 1b
gives three reference projection images that depict the path followed
through the image during navigation. The reference projections
are maximum-intensity projections of the 3D image data onto the
0 lung pressure).
Figure 1a illustrates a
sample navigation sequence through the bronchial passages. Each
view, labeled View 1, View 2, etc., depicts a 3D rendered image
along the navigation path. In the center of View 1, the dark cavity surrounded by
the tube is the main bronchus (a hollow cavity). The orange structures
outside the bronchus are the lungs. Each successive view depicts
what one observes while traversing down the bronchus and into
the lung to the right. An important consideration while navigating
is to know your current orientation in the data. Fortunately, since
we have a 3D copy of the anatomy (the 3D EBCS image), we can easily
compute and display this information. Figure 1b
gives three reference projection images that depict the path followed
through the image during navigation. The reference projections
are maximum-intensity projections of the 3D image data onto the ![]() (Transverse),
(Transverse), ![]() (Sagittal), and
(Sagittal), and ![]() (Coronal) planes [8]. The
green line on these images depicts a projection of the 3D path traversed,
and the red dot indicates the last viewing site considered. The bright structures
in these projections are the bronchial passages (image gray scale was inverted
to make the projections).
(Coronal) planes [8]. The
green line on these images depicts a projection of the 3D path traversed,
and the red dot indicates the last viewing site considered. The bright structures
in these projections are the bronchial passages (image gray scale was inverted
to make the projections).
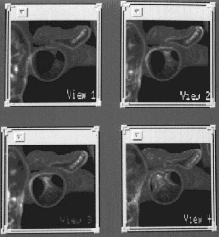
Figure 9. Illustration of temporal coherence for interactive navigation through a 3D pulmonary image. Same data as Figure 1 used. View 1 corresponds to View 4 of Figure 1a. Views 2, 3, and 4 correspond to the views that precede View 5 of Figure 1a. So, Views 1-4 of this figure and View 5 of Figure 1a constitute a five-consecutive-view sequence along the navigation path. These views occur about the sharp bend along the navigation path shown in Figure 1b. (See color plate at end of proceedings.)
The sequence of views shown in Figure 1a only represent a sampling of the views encountered during navigation. The complete path depicted in Figure 1b actually required roughly 50 views (i.e., 50 movements were needed to travel from start to finish). The views generally change minutely as one navigates. This is the temporal coherence phenomenon. Figure 9 shows a manifestation of this phenomenon at the large bend near the end of the navigation path (observe the path bend in the Sagittal view in Figure 1b). The views correspond to four successive views along the path -- the views do not change greatly even in a region where we make relatively severe movements. As it turns out, View 1 in Figure 9 corresponds to View 4 of Figure 1a. Also, Figure 9's View 4 directly precedes View 5 of Figure 1a. Hence, Views 1-4 of Figure 9 and View 5 of Figure 1a constitute a five-view sequence.
Next, we present timing results for navigation, as shown in Tables 1-3.
Results are given for viewing pyramids of two different sizes.
Table 1 shows the results for a ![]() viewing pyramid.
Table 2 considers the same size n=64, but considers obtaining a double-sized
display; the double-sized display was obtained by interpolating the viewing
screen pixels (i.e., a
viewing pyramid.
Table 2 considers the same size n=64, but considers obtaining a double-sized
display; the double-sized display was obtained by interpolating the viewing
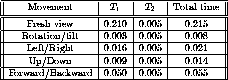
screen pixels (i.e., a ![]() view is presented). In Table 3,
the results are shown for a
view is presented). In Table 3,
the results are shown for a ![]() viewing pyramid. All
timing results shown in Tables 1-3 correspond to actual average time per movement.
In each case, a viewing ray was stored as 4 partial segments. Thus,
viewing pyramid. All
timing results shown in Tables 1-3 correspond to actual average time per movement.
In each case, a viewing ray was stored as 4 partial segments. Thus,
![]() (16 views in total) rotations can be obtained by using this set
of partial segment results. If necessary, a fresh set of partial segments
were computed using brute-force ray casting after every 4 rotations about
either the horizontal or vertical axis of the viewing screen.
(16 views in total) rotations can be obtained by using this set
of partial segment results. If necessary, a fresh set of partial segments
were computed using brute-force ray casting after every 4 rotations about
either the horizontal or vertical axis of the viewing screen.
(For all tables, ![]() = time required in secs. for ray-casting and compositing,
and
= time required in secs. for ray-casting and compositing,
and ![]() time required in secs. for interpolation of viewing screen.)
time required in secs. for interpolation of viewing screen.)
Table 1. ![]() viewing pyramid.
viewing pyramid.
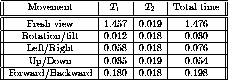
Table 2. ![]() viewing pyramid (double-sized)
viewing pyramid (double-sized)
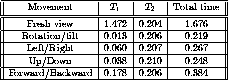
Table 3. ![]() viewing pyramid.
viewing pyramid.
The timing results illustrate that incremental rotations and
translations are performed extremely quickly compared to computation of
fresh views. This significantly low time for incremental movements
is the key to fast navigation since it helps offset
the computational cost involved in computing fresh views
at intermediate stages of the navigation. The ``fresh view'' computation
basically corresponds to Step 1 of the method summarized in Figure 2.
This time can be amortized over the time required for computing additional
views. It always must be done initially. But it can be avoided
much of the time during navigation. In fact, if ![]() -voxel segments are
stored and the orientation
remains within
-voxel segments are
stored and the orientation
remains within ![]() units of x- and y-displacement
of the initial viewing direction, then it never needs to be
done again.
Note that for the n=32
case, this fresh view computation is still done at essentially
interactive speed. Also, we have not tried to amortize the cost of
obtaining a fresh view over the incremental rotations as was
discussed in Section 3.4. Such a scheme would increase the
time somewhat, but mostly avoid the need for slow computations
from scratch. It's also important to realize that we implemented
a complex rendering operation. Further speedup can be obtained if
true-gradient shading is not needed. The fresh views in particular
can be computed much faster if a true 3D gradient is not calculated at each
sample along the ray.
units of x- and y-displacement
of the initial viewing direction, then it never needs to be
done again.
Note that for the n=32
case, this fresh view computation is still done at essentially
interactive speed. Also, we have not tried to amortize the cost of
obtaining a fresh view over the incremental rotations as was
discussed in Section 3.4. Such a scheme would increase the
time somewhat, but mostly avoid the need for slow computations
from scratch. It's also important to realize that we implemented
a complex rendering operation. Further speedup can be obtained if
true-gradient shading is not needed. The fresh views in particular
can be computed much faster if a true 3D gradient is not calculated at each
sample along the ray.
The average time for rotations can be decreased even further by dividing
a ray into more partial segments. For
a ![]() viewing pyramid,
viewing pyramid, ![]() = 64
rotational views can be obtained quickly by storing segments of length 8.
The slight disadvantage of increasing the number of partial segments arbitrarily
is, however, the greater computation required for performing forward/backward
movements. This increase in computation results from the need to
add/remove more planes of data for the entire set of
partial-segment arrays. Hence, a trade-off exists in choosing the
partial-segment lengths into which a viewing ray is divided.
= 64
rotational views can be obtained quickly by storing segments of length 8.
The slight disadvantage of increasing the number of partial segments arbitrarily
is, however, the greater computation required for performing forward/backward
movements. This increase in computation results from the need to
add/remove more planes of data for the entire set of
partial-segment arrays. Hence, a trade-off exists in choosing the
partial-segment lengths into which a viewing ray is divided.
If brute-force ray-casting were done all computations would be on the order of the fresh-view numbers. This would be true, even for the relatively simple Left/Right and Up/Down movements, because the viewing pyramid for an arbitrary viewing site generally is not situated such that it ``lines up'' exactly with the known voxel data.